


- Getting Started
- Administration Guide
-
User Guide
- An Introduction to Wyn Enterprise
- Document Portal for End Users
-
Data Governance and Modeling
- Data Binding Concepts
-
Introduction to Data Sources
- Connect to Oracle
- Connect to SQL Server
- Connect to MySQL
- Connect to Postgres
- Connect to Snowflake
- Connect to SQLite
- Connect to DM
- Connect to TiDB
- Connect to AnalyticDB(MySQL)
- Connect to GreenPlum
- Connect to TimeScale
- Connect to Amazon Redshift
- Connect to MariaDB
- Connect to ClickHouseV2
- Connect to MonetDB
- Connect to Kingbase
- Connect to GBase8a
- Connect to GBase8s
- Connect to ClickHouse
- Connect to IBM DB2
- Connect to IBM DB2 iSeries/AS400
- Connect to Google BigQuery
- Connect to Hive (beta)
- Connect to ElasticSearch (beta)
- Connect to Hana
- Connect to Excel
- Connect to JSON
- Connect to CSV
- Connect to XML
- Connect to MongoDB
- Connect to ElasticSearchDSL
- Connect to InfluxDB
- Connect to ODBC
- Connect to OData
- Introduction to Data Model
- Introduction to Direct Query Model
- Introduction to Cached Model
- Introduction to Datasets
- How To
- Secure Data Management
- Working-with-Resources
- Working with Reports
- Working with Dashboards
- View and Manage Documents
- Understanding Wyn Analytical Expressions
- Section 508 Compliance
- Developer Guide
Connect to InfluxDB
InfluxDB is a time series database used to read and write data at high speed in real time. In this section, you will find information on the following topics,
To Create InfluxDB
To create an InfluxDB in Wyn Enterprise, navigate to the Resource Portal and follow the below instructions,
Click the + icon and then, select the Create Data Source option.
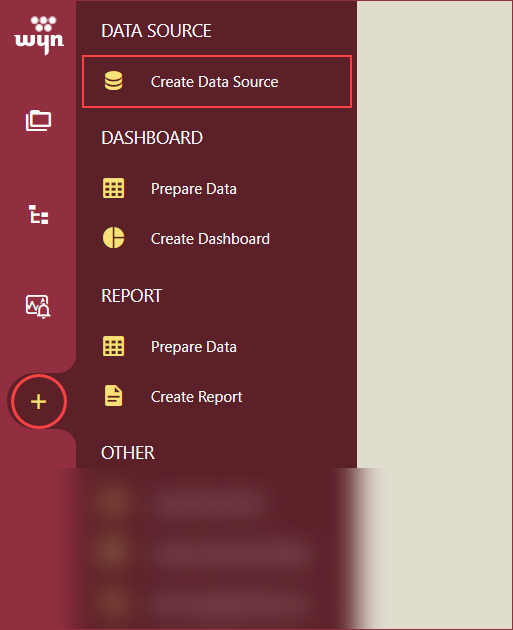
Select the InfluxDB option from the data source list on the left or from the icon view under the NoSQL section on the right.

Fill in the database configuration information. The database configuration items are described in the table below. Click the Test Connection button to verify the data source connection. Once the connection is tested and validated, you will receive a notification of a successful connection. Click the Create button to finish.
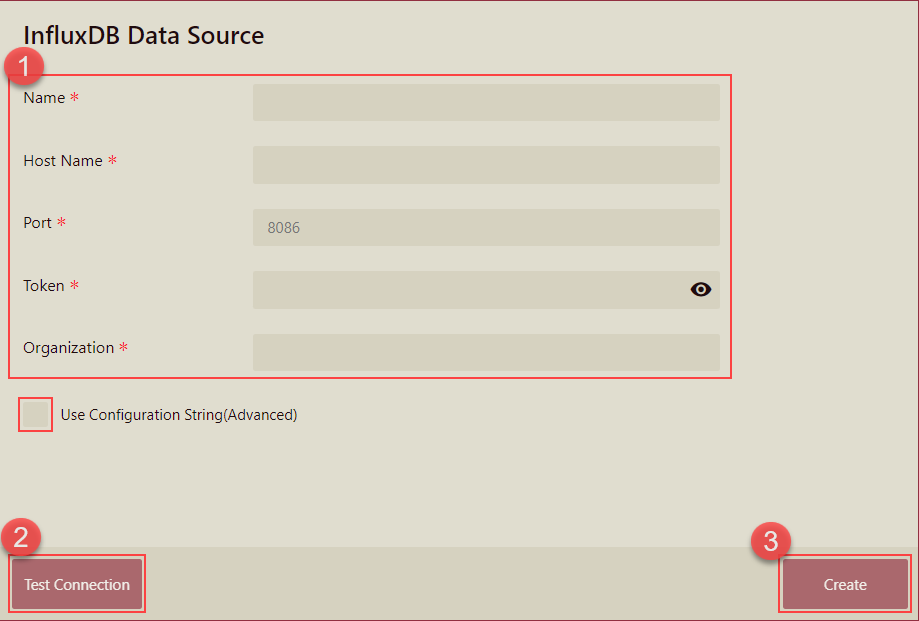
Field | Description |
|---|---|
Name* | The name of the data source that you want to specify. |
Hostname* | A hostname or address. |
Port* | A port number, the default is 9200. |
UserName | A user name to connect to the ElasticSearchDSL database. |
Password | A password of the ElasticSearchDSL user. |
Use Configuration String (Advanced) | Use this option to connect to the data provider through a connection string. The format of the connection string is:
|
* Required fields
You can view the newly added data source in the Categories tab of the Resource Portal.
Salient Points
InfluxDB is a temporal database. Data elements of InfluxDB are listed and described in the following table,
Data Element | Description |
|---|---|
timestamp | Data stored in InfluxDB has a _time column that stores timestamps. |
measurement | Measurement names are strings and measurement acts as a container for tags, fields, and timestamps. _measurement column shows the name of the measurement. |
field | A field includes a field key stored in the _field column and a field value stored in the _value column. |
field key | A field key is a string that represents the name of the field. In the sample data below, bees and ants are field keys. |
field value | A field value represents the value of an associated field. Field values can be string, float, integers, or boolean. Field values in the sample data show the number of bees at a specified time: 23, 28 and the number of ants at a specified time: 30, 32. |
field set | A field set is a collection of field key-value pairs associated with a timestamp. A measurement requires at least one field. The sample data includes the following field sets, census bees=23i, ants=30i 1566086400000000000 census bees=28i,ants=32i 1566086760000000000 |
tags | Tags include tag keys and tag values that are stored as strings. |
tag key | Tag keys in the sample data are location and scientist. |
tag value | Tag key - location has two tag values: klamath and portland. Tag key - scientist, has two tag values: anderson and mullen. |
tag set | Tag key - location has two tag values: klamath and portland. Tag key - scientist, has two tag values: anderson and mullen. |
series | - A series is a collection of points that share a measurement, tag set, and field key. - A series includes timestamps and field values for a given series key. From the sample data below, an example of a series key and the corresponding series is, #series key - census,location=klamath,scientist=anderson bees #series - 2019-08-18T00:00:00Z 23 2019-08-18T00:06:00Z 28 |
The InfluxDB library supporting C# is maintained at the GitHub - influxdb-client-csharp. Note the following,
The official library supports Flux language and does not support SQL.
InfluxDB can query data using InfluxQL, Flux, and APIs.
InfluxQL language is similar to SQL however, it is used only for API query usage.
InfluxQL and Flux are functionally equivalent. Only the codes of both languages look different. See this help article for more information on the parity of InfluxQL and Flux.
Flux is an open-source functional data scripting language. See this help article for more information on Flux language.
The following table lists the InfluxDB data types as compared to the C# data types,
InfluxDB Datatype | C# Datatpe |
|---|---|
dateTime:RFC3339 | DateTimeOffset |
dateTime:RFC3339Nano | DateTimeOffset |
string | String |
double | Double |
boolean | Boolean |
long | Int64 |
unsignedLong | UInt64 |
base64Binary | Byte[] |
duration | TimeSpan |
Connection configurations for InfluxDB: A client can be constructed using a connection string that can contain the InfluxDBClientOptions parameters encoded into the URL.
connectionString = "http://localhost:8086?token=myToken&org=myOrg")Options supported in the connection string are listed and described in the following table,
Property Name | Default Value | Description |
|---|---|---|
org | - | default destination organization for writes and queries |
bucket | - | default destination bucket for writes |
token | - | the token to use for the authorization |
logLevel | NONE | rest client verbosity level |
timeout | 10000 ms | The timespan to wait before the HTTP request times out. |
allowHttpRedirects | false | Configure automatically following HTTP 3xx redirects |
verifySsl | true | Ignore Certificate Validation Errors when false |
Note: The timeout supports ms, s, and m as unit. Default value is in milliseconds.
InfluxDB supports multi-table queries. When the Flux query results in multiple tables, flatten the data to a single table, the same columns will be merged, and the case of no such column in one table will be filled as null.
InfluxDB supports only Native Query Dataset.
Query Strategy
Queries in InfluxDB are performed using the Flux language. For example,
a. Insert the following data into the InfluxDB data source,
PointData.Measurement("measurementName")
.Tag("location", "west")
.Field("value", 55D)
.Timestamp(DateTime.UtcNow.AddSeconds(-10), WritePrecision.Ns);
PointData.Measurement("measurementName")
.Tag("location", "north")
.Field("value", 56D)
.Timestamp(DateTime.UtcNow.AddSeconds(-10), WritePrecision.Ns);
PointData.Measurement("measurementName")
.Tag("location", "west")
.Field("value", 57D)
.Timestamp(DateTime.UtcNow, WritePrecision.Ns);
PointData.Measurement("measurementName")
.Tag("location", "north")
.Field("value", 58D)
.Timestamp(DateTime.UtcNow, WritePrecision.Ns);b. Now run the following query using the Flux statement,
from(bucket: "bucketName")
|> range(start: -10m, stop: now())
|> filter(fn: (r) => r._measurement == "measurementName")c. Above query will result in two tables. However, the end result will be a single table as listed in the Actual Table below.
Table 1:
result | table | _start | _stop | _time | _value | _field | _measurement | location |
|---|---|---|---|---|---|---|---|---|
_result | 0 | 2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:03:50Z | 56 | value | temperature | north |
_result | 0 | 2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:04:00Z | 58 | value | temperature | north |
Table 2:
result | table | _start | _stop | _time | _value | _field | _measurement | location |
|---|---|---|---|---|---|---|---|---|
_result | 1 | 2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:03:50Z | 55 | value | temperature | west |
_result | 1 | 2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:04:00Z | 57 | value | temperature | west |
Actual Table:
_start | _stop | _time | _value | _field | _measurement | location |
|---|---|---|---|---|---|---|
2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:03:50Z | 56 | value | measurementName | north |
2022-03-18T02:55:32Z | 2022-03-18T03:05:32Z | 2022-03-18T03:04:00Z | 58 | value | measurementName | north |
The following are the main considerations of the above result,
The _time fields in the two tables are duplicated and the data is not easy to use.
Although the structure of the two tables is the same, the representation is different.
If the data in both table1 and table2 needs to be used, a more logical solution would be to filter using the filter function.
If more than one table exists in the result set returned by InfluxDB, then only the first table will be returned.
The returned table will remove the result and table columns because the values of these two columns are not meaningful for the use of the data.
Limitations
Note the following limitation of InfluxDB,
Any query that does not return a table is treated as a SQL execution error.
When using multi-valued parameters, you must ensure that the first parameter of a multi-valued parameter query returns a table.
When a query returns multiple tables, you must ensure that the _value field type is the same for each table.
The _value field in multiple tables must be of the same type, otherwise, the data source will report an error.