-
Interactive DashboardsCreate interactive BI dashboards with dynamic visuals.
-
End-User BI ReportsCreate and deploy enterprise BI reports for use in any vertical.
-
Wyn AlertsSet up always-on threshold notifications and alerts.
-
Localization SupportChange titles, labels, text explanations, and more.
-
Wyn ArchitectureA lightweight server offers flexible deployment.
-
 Wyn Enterprise 7.1 is ReleasedThis release emphasizes Wyn document embedding and enhanced analytical express...
Wyn Enterprise 7.1 is ReleasedThis release emphasizes Wyn document embedding and enhanced analytical express... -
 Choosing an Embedded BI Solution for SaaS ProvidersAdding BI features to your applications will improve your products, better serve your customers, and more. But where to start? In this guide, we discuss the many options.
Choosing an Embedded BI Solution for SaaS ProvidersAdding BI features to your applications will improve your products, better serve your customers, and more. But where to start? In this guide, we discuss the many options.
-
Visual GalleryInteractive sample dashboards and reports.
-
BlogExplore Wyn, BI trends, and more.
-
WebinarsDiscover live and on-demand webinars.
-
Customer SuccessVisualize operational efficiency and streamline manufacturing processes.
-
Knowledge BaseGet quick answers with articles and guides.
-
VideosVideo tutorials, trends and best practices.
-
WhitepapersDetailed reports on the latest trends in BI.
-
 Choosing an Embedded BI Solution for SaaS ProvidersAdding BI features to your applications will impr...
Choosing an Embedded BI Solution for SaaS ProvidersAdding BI features to your applications will impr... -
- Getting Started
- Administration Guide
-
User Guide
- An Introduction to Wyn Enterprise
- Document Portal for End Users
-
Data Governance and Modeling
- Data Binding Concepts
-
Introduction to Data Sources
- Connect to Oracle
- Connect to SQL Server
- Connect to MySQL
- Connect to Postgres
- Connect to Snowflake
- Connect to SQLite
- Connect to DM
- Connect to TiDB
- Connect to AnalyticDB(MySQL)
- Connect to GreenPlum
- Connect to TimeScale
- Connect to Amazon Redshift
- Connect to MariaDB
- Connect to ClickHouseV2
- Connect to MonetDB
- Connect to Kingbase
- Connect to GBase8a
- Connect to GBase8s
- Connect to ClickHouse
- Connect to IBM DB2
- Connect to IBM DB2 iSeries/AS400
- Connect to Doris
- Connect to OceanBase(MySQL)
- Connect to Kylin
- Connect to StarRocks
- Connect to Google BigQuery
- Connect to Hive (beta)
- Connect to ElasticSearch (beta)
- Connect to Hana
- Connect to Excel
- Connect to JSON
- Connect to CSV
- Connect to XML
- Connect to MongoDB
- Connect to ElasticSearchDSL
- Connect to InfluxDB
- Connect to SSAS
- Connect to ODBC
- Connect to OData
- Connect to TDengine
- Connect to Teradata
- Connect to Custom Provider
- Introduction to Data Model
- Introduction to Direct Query Model
- Introduction to Cached Model
- Introduction to Datasets
- Data Flow Designer
- Secure Data Management
- How To
- WynSQL
- View and Manage Documents
- Working with Resources
- Working with Reports
- Working with Dashboards
- Working with Notebooks
- Wyn Analytical Expressions
- Section 508 Compliance
- Subscribe to RSS Feed for Wyn Builds Site
- Developer Guide
Connect to ElasticSearchDSL
To create an ElasticSearchDSL data source in Wyn Enterprise, follow these steps.
Note: Wyn Enterprise supports 7.x version of ElasticSearch DSL valid up to 7.17.
On the Resource Portal, navigate to Create (+) > Create Data Source.
Select ElasticSearchDSL in the data source list on the left or in the icon view on the right.
Fill in the database configuration information for the selected data source.
Field | Description |
|---|---|
Name* | The name for the data source that you want to specify. |
Hostname* | A host name or address. |
Port* | A port number, the default is 9200. |
UserName | A user name to connect to the ElasticSearchDSL database. |
Password | A password of the ElasticSearchDSL user. |
Use Configuration String (Advanced) | Use this option to connect to the data provider through a connection string. The format of the connection string is: |
* Required fields
Click Test Connection to verify the data source connection. If the data source is available, and the credentials filled are correct, you receive a notification on successful connection.
Click Create after the successful connection.
You can view the added data source in the Categories tab of the Resource Portal.
Salient Points
No schema is generated on previewing the data source.
The dataset cannot be designed by dragging and dropping the tables from the ElasticSearchDSL data source.
The dataset designer only supports the creation of custom SQL tables with native DSL.
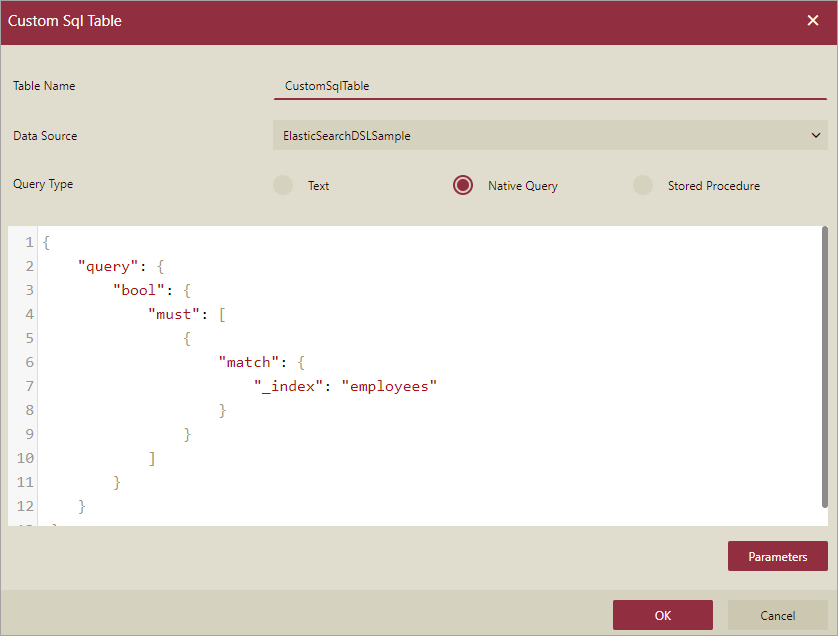
This is the only way to read the data from the ElasticSearchDSL data source. For more information about DSL queries, please visit this article.
Additional Points
The default host is an HTTP URL. If you have an HTTPS URL, you can add the HTTPS in front of your host.
If the cluster status is red, you will face an error.
To use the Date type field in the query, you must add a calculated field to convert it to a DateTime column.
When sorting the result using the sort keyword, you must use the [ and ] to quote the original JSON. For example, "sort": [{"_id":"desc"}].
When sorting the result using the order keyword, use the [ and ] to quote the original JSON. For example, "order": [{"_id":"desc"}].
When using the metrics keyword to get the result, you must use [ and ] to quote the original JSON. For example, "metrics": [{"field": "experience"}].
Limitations
Here are a few limitations of using ElasticSearch DSL data source:
Does not support incremental refresh on a dashboard dataset.
Only the count of elements of the inner bucket table is returned if the element is a bucket table within the element of the bucket table.
When using parameters in the DSL query, you need to guarantee the exact name, type, and count of the column and must return a successful response when the value is empty or irregular.
The following aggregation functions are not supported in Wyn Enterprise – pipeline, bucket (including Categorize text, Children, Composite, Geo-distance, Geohash grid, Geotile grid, Global, Nested, Parent, and Reverse nested), and metric (including Geo-bounds, Geo-centroid, and Geo-Line).
An empty response or data is returned when a user sends a JSON request. In some cases, a table with no rows and columns is returned, or an error is shown. So, in such cases you must follow the below rules:
i. Get the table name from query.term node.
ii. Get the table name from query.bool.must.match._index node (first element).
When using user input parameters without a default value, only parameters of types - text or boolean are supported.
If the DSL query filter is empty while using the official client Nest, all the data of the current table is returned.
Does not support the text value to be the same as the parameter name because dataset parameters are replaced in the Elasticsearch DSL query.
When using parameters to achieve the result, there are chances that an empty table is returned. This is because there are no columns in the table and therefore the applied aggregation fails to return the whole columns.
This is applicable in the case of Matrix Stats, Percentile Ranks, Percentile, Top Hits, Top Metrics, Diversified Sampler, Multi Terms, Sampler, and Significant Text aggregations.
When using the parameter for operator node in the match node and the parameter type is set to user input. Then, you must input 'and' or 'or', or else you will face an error.
If the JSON query fails to parse using the official client Nest, then change 'N/A' to any number.
{ "size": 0, "aggs": { "tag_cardinality": { "cardinality": { "field": "tags", "missing": "N/A" } } } }An error is shown if you include a field in the includes node, which does not exist in the current mapping.